Pandasで必要な列だけを取り出す
以前の投稿でフィルタ操作(つまり行の絞り込み)を紹介しましたが、今回は列の操作について紹介します。
データは前回同様、総務省統計局のデータを拝借します。
コード紹介
# インポート import pandas as pd # ファイルの取り込み df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3) # 「時間軸コード」と「時点」列を削除 df_drop = df.drop( columns=['時間軸コード', '時点'] ) # もしくはdf_drop = df.drop(['時間軸コード', '時点'], axis=1) # 「男」、「女」列だけを取り出す df_select = df[['男','女']] # もしくはdf_select = df.loc[:, ['男','女']]
出力結果
- 元データ
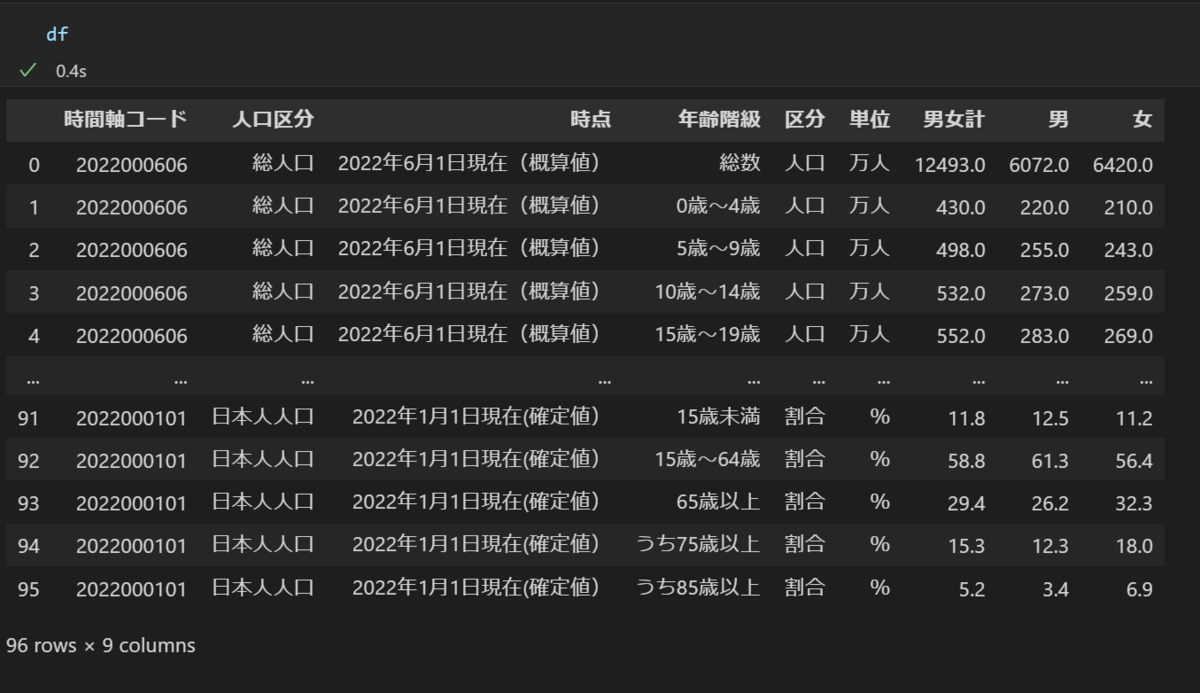
- 列を削除したデータ
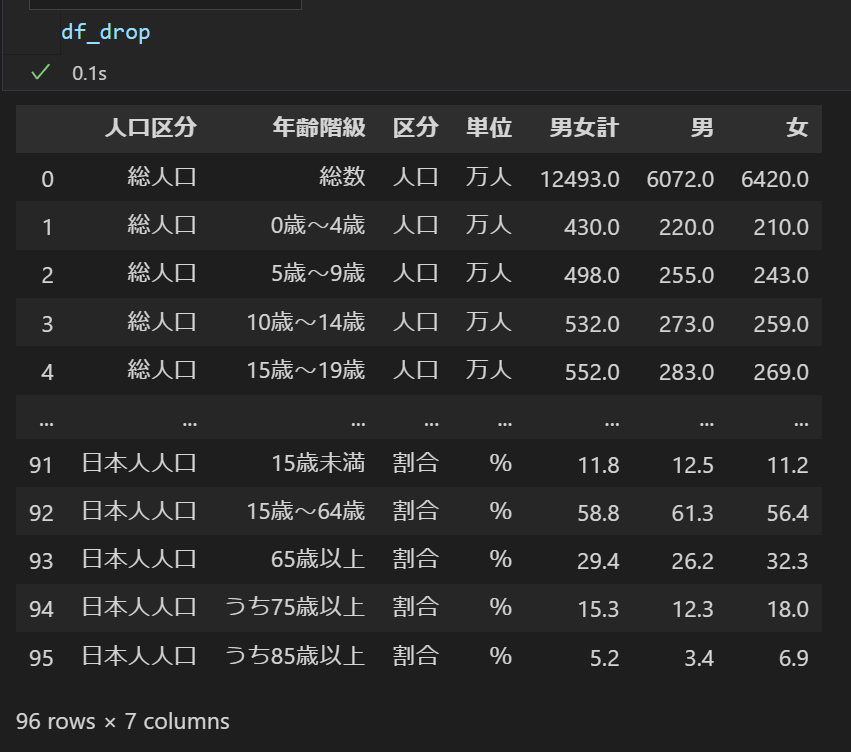
- 列を選択したデータ
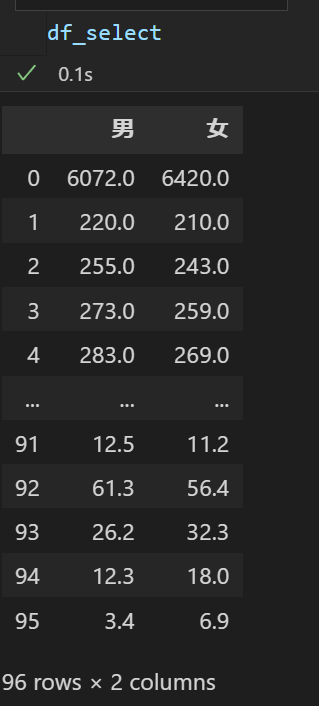
少し解説
drop関数
列の削除は、一般的にはdf.drop(['時間軸コード', '時点'], axis=1)を使います。
こちらの良いところは、axis=0(もしくはオプションなし)にすると列の削除もできるところです。
ただし、私の場合列って0だっけ?1だっけ?といつも悩むので、column=を使う方が便利だと思っています。
loc関数
こちらも今回コメントアウトしていますが、loc関数を使うといろいろと応用ができます。
loc[(取りたい行), (取りたい列)]という構文になります。
今回行はすべて取るため、:としていますが、例えば以下のようなことが簡単にできます。
- 50行まで取る→
df.loc[:50, ['男','女']] - 40~60行を取る →
df.loc[40:60, ['男','女']] - 70行以降を取る →
df.loc[70:, ['男','女']]