2つのデータフレームを1つに結合(行、列の追加)
前回はPandasのconcatを使って行や列にデータフレイムを追加する方法を紹介しました。
その中のオプションjoinで、内部結合と外部結合の方法を紹介しましたが、このオプションには左外部結合(または右外部結合)がありません。
ただ、少し工夫することでできる方法がありますので、紹介します。
やりたいこと
左外部結合(df1の列(a,b,c)だけで行を追加)
コード紹介
# import import pandas as pd # データセットを作る df1 = pd.DataFrame({'a':[1,4], 'b':[2,5], 'c':[3,6]}) df2 = pd.DataFrame({'a':[7], 'b':[8], 'd':[9]}) # 左外部結合(行) df_tmp1 = pd.DataFrame([], columns=df1.columns) df_tmp2 = pd.concat([df2, df_tmp1]) df3 = pd.concat([df1, df_tmp2], join='inner') # インデックスリセット df3 = df3.reset_index(drop=True) df3
出力結果

少し解説
df_tmp1
df1の列を入れたからのデータフレームを作っています。
pd.DataFrame([], columns=df1.columns)
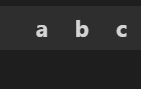
df_tmp2
上記の空のデータフレームとdf2を結合することで、df1にしかない列を追加します。
pd.concat([df2, df_tmp1])
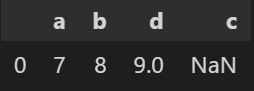
df3
あとはdf2にしかない列(d)は不要ですので、innner joinします。
pd.concat([df1, df_tmp2], join='inner')
他にも良い方法があるかもしれませんが、取り急ぎ。
2つのデータフレームを1つに結合(行、列の追加)
機械学習などを行うとき、複数のデータを1つにまとめたりしたい時があります。その時に便利なのがPandasのconcatです。
やりたいこと
こんな感じで、2つのデータフレームを1つに結合。

コード紹介
# import import pandas as pd # データセットを作る df1 = pd.DataFrame({'a':[1,4], 'b':[2,5], 'c':[3,6]}) df2 = pd.DataFrame({'a':[7], 'b':[8], 'd':[9]}) # データの結合(行) df3 = pd.concat([df1, df2], axis=0, join='outer') # axis, joinは省略可 # インデックス初期化 df3 = df3.reset_index() # 結合前のindexが不要な場合はdf3.reset_index(drop=True) df3
出力結果
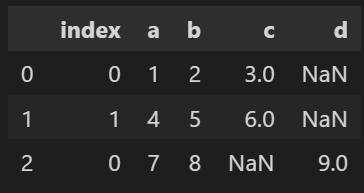
少し解説
concatの引数 join について
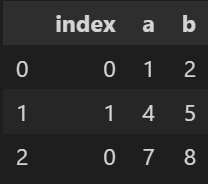
デフォルトはouterですが、innerとすることで内部結合(共通している列だけ残す)になります。
今回の例の場合、'a'と'b'が共通なので、以下のようになります。
python df3 = pd.concat([df1, df2], axis=0, join='inner')
concatの引数 axis について
デフォルト0の場合行に追加していきますが、1にすると列に追加になります。
python df3 = pd.concat([df1, df2], axis=1, join='outer')
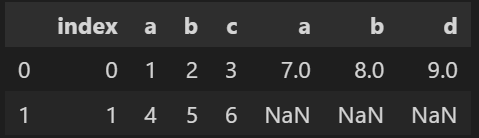
※この場合列aや列bが重複してしまうので、あまり良い例ではありません。
インデクスの初期化(reset_index)について
reset_index()を入れないと、以下のようにインデックスが結合前のdf1, df2のインデックスを引き継ぎ、重複してしまいます。
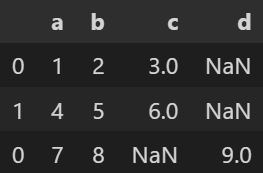
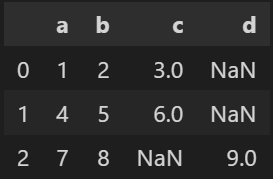
そのため、結合した後は必ずreset_index() を行いましょう。
結合前のインデックスはindexという列名でデータフレームに保管されますが、不要な場合は python reset_index(drop=True)とします。
PandasのDataFrameを1行ずつ(もしくは1列ずつ)取り出す
取得したデータを行ごとに操作したいことってありますよね。
例えば、機械学習のモデルを作った後に、テスト用のデータを行ごとに推論させて結果を保存する、というようなときに、便利な使い方を紹介します。使う関数はiterrows()を使います。
コード紹介
# import import pandas as pd # データセットを作る df = pd.DataFrame({'a':[10,20,30],'b':['A','B','C'],'c':[True,False,True]}) # a b c # 0 10 A True # 1 20 B False # 2 30 C True print("列aの中身を表示") # 行を繰り返す for index, row in df.iterrows(): print(index, row['a']) print("2行目の中身を表示") # 列を繰り返す for header, column in df.iteritems(): print(header, column[1])
出力結果

少し解説
for index, row in df.iterrows(): とすることで、dfの中身を行ごとに取り出して繰り返す、ということになります。
初めの引数のindexには行番号、2番目の引数のrowには取得したデータが入ります。
また、iterrows()の代わりにiteritems()を使うと列ごとに取得するようになります。
簡単で便利ですね。
Pandasで必要な列だけを取り出す(複数の条件)
以前のブログで列のフィルタをかける方法を紹介しました。
今回はその応用で、複数の条件でフィルタをかける方法です。
簡単にできるかと思ったら結構ハマってしまったので、、紹介します。
データはこちらを使っています。
コード紹介
# インポート import pandas as pd import matplotlib.pyplot as plt # ファイルの取り込み df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3) # 人口区分が「総人口」かつ区分が「人口」かつ時間軸コードが2022000606かつ年齢階級が「うち」から始まらないものを抽出 df2 = df[(df['人口区分'] == '総人口') & (df['区分'] == '人口') & (df['時間軸コード'] == 2022000606) & ~(df['年齢階級'].str.startswith('うち'))] df2
出力結果

少し解説
通常PythonでAND条件、OR条件、NOT条件などを使うときはand, or, notを使います。
例. if ( a == 1 and not(b < 3) )
ただ、Pandasを使う場合は &, |, ~を使います。
これさえ分かっていれば何も難しくはないのですが、知らないとエラーも不親切なため、原因究明が難しいです。
データの傾向をつかむ(uniqueで文字列カテゴリを確認)
データを見るとき、print(df)やprint(df.head(10))などをしますが、これだとすべてのデータを見ることはできません。
とはいえ全部のデータを見るのは至難の業なので、データ解析にはざっくりと傾向をつかむことが大事です。
今回は文字列データの傾向をつかむことを考えます。
データはこちらを使っています。
コード紹介
# インポート import pandas as pd # ファイルの取り込み df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3) # 人口区分の中にあるデータを確認(重複削除) df['人口区分'].unique()
出力結果

少し解説
Pandasのunique()関数を使うことで、重複を削除した状態で表示することができます。
これを使えば、「総人口と日本人人口の2つがデータの中にあるのか。じゃあ今回は総人口のデータを使おう」と考えれば、そのデータだけを取り出すdf2 = df[(df['人口区分'] == '総人口')]という次の解析のアクションにつなげられるわけです。
Matplotlibでグラフ化。日本人が詰まる日本語化はこの1行で解決!
今回はMatplotlibでのグラフ化について紹介します。
何回かに分けて説明していこうと思いますが、一番詰まるのが日本語化です。。
よくラベルを全部英語に直して、などされている人もいますが、データの中身にも日本語が入っていたりするので、できれば日本語でそのまま出したいですね。
データはいつものように こちらのデータを使っています。
Matplotlibの日本語化はこの1行
plt.rcParams['font.family'] = "Meiryo"
これだけです。
コード紹介
# インポート import pandas as pd import matplotlib.pyplot as plt # ファイルの取り込み df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3) # 日本語化 plt.rcParams['font.family'] = "Meiryo" # # グラフ表示 # # タイトルの設定 plt.title("男性の人口") # y軸の設定 # plt.ylabel('人口') # グラフの描画 plt.plot(df.index, df['男']) # グラフを表示 plt.show()
出力結果
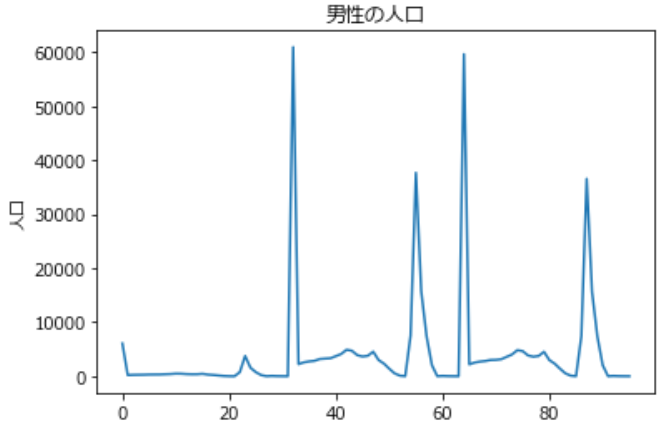
少し解説
今回Meiryoを使いましたが、その他Windows環境ですとMS Gothicなども使えます。(個人的にはタイプしやすいMeiryoを使っています)
注意点としては、私の環境はWindows 10ですので、それ以外のOS(特にMac, Linux)ではまた使えるフォントが異なると思います。
ちなみに、デフォルトのフォントを使うと以下のように、ワーニングとともに文字化けされた結果が表示されます。
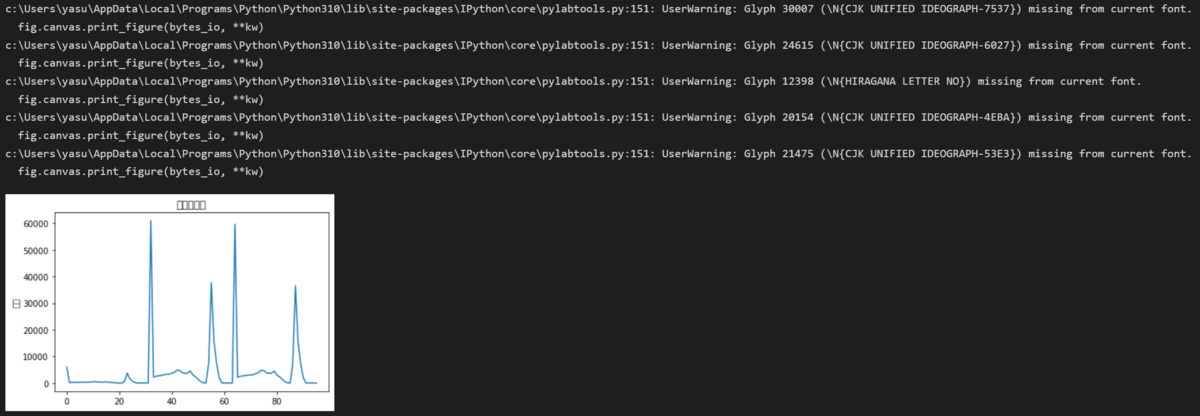
Pandasで必要な列だけを取り出す
以前の投稿でフィルタ操作(つまり行の絞り込み)を紹介しましたが、今回は列の操作について紹介します。
データは前回同様、総務省統計局のデータを拝借します。
コード紹介
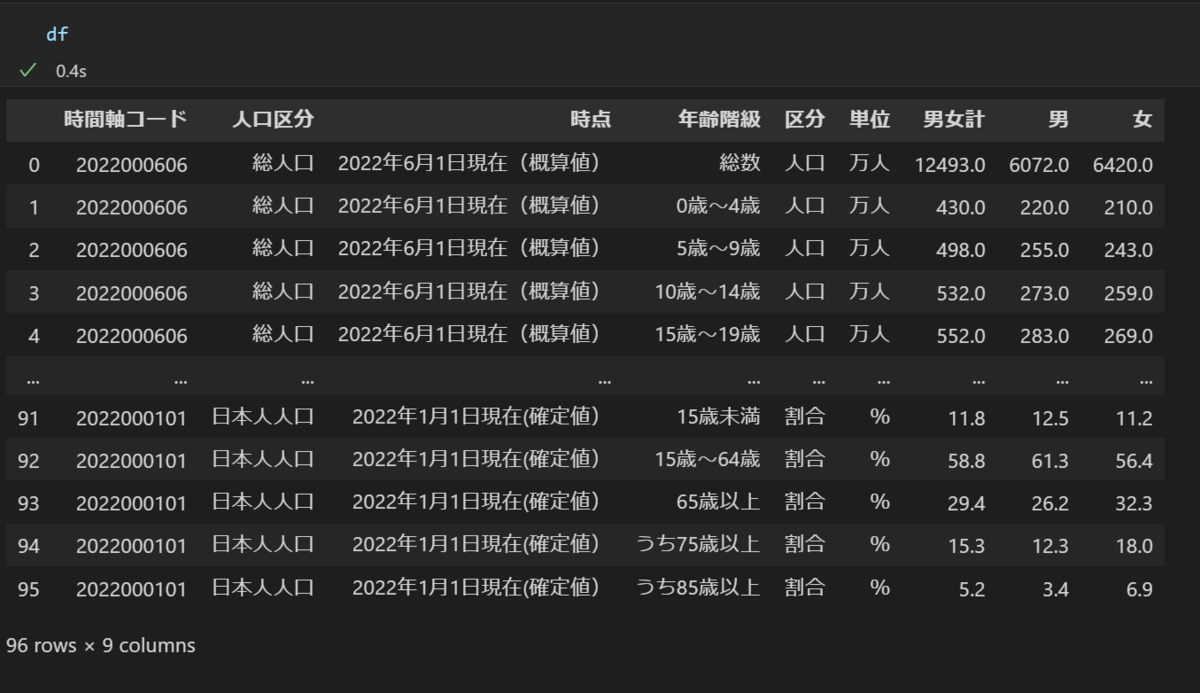
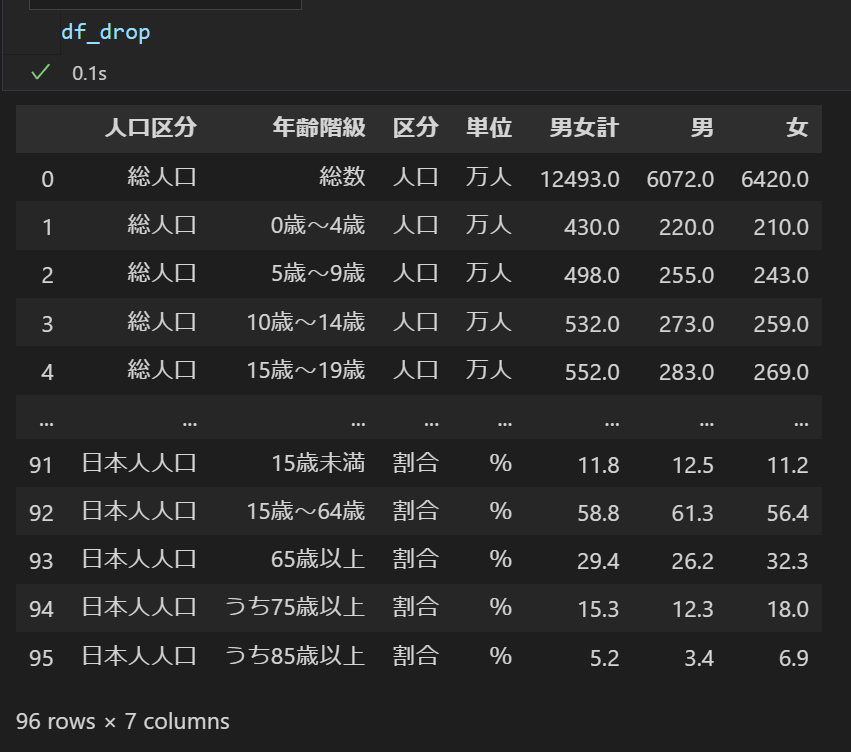
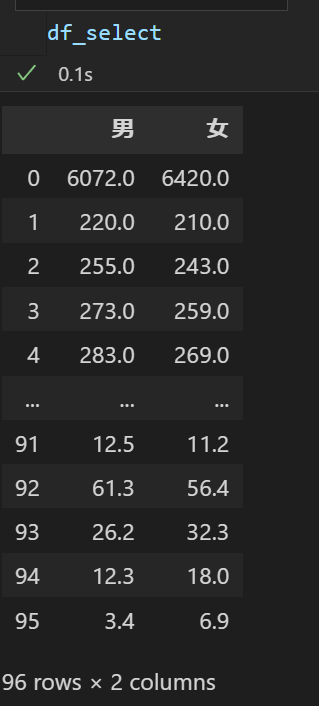
# インポート import pandas as pd # ファイルの取り込み df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3) # 「時間軸コード」と「時点」列を削除 df_drop = df.drop( columns=['時間軸コード', '時点'] ) # もしくはdf_drop = df.drop(['時間軸コード', '時点'], axis=1) # 「男」、「女」列だけを取り出す df_select = df[['男','女']] # もしくはdf_select = df.loc[:, ['男','女']]
出力結果
- 元データ
- 列を削除したデータ
- 列を選択したデータ
少し解説
drop関数
列の削除は、一般的にはdf.drop(['時間軸コード', '時点'], axis=1)を使います。
こちらの良いところは、axis=0(もしくはオプションなし)にすると列の削除もできるところです。
ただし、私の場合列って0だっけ?1だっけ?といつも悩むので、column=を使う方が便利だと思っています。
loc関数
こちらも今回コメントアウトしていますが、loc関数を使うといろいろと応用ができます。
loc[(取りたい行), (取りたい列)]という構文になります。
今回行はすべて取るため、:としていますが、例えば以下のようなことが簡単にできます。
- 50行まで取る→
df.loc[:50, ['男','女']] - 40~60行を取る →
df.loc[40:60, ['男','女']] - 70行以降を取る →
df.loc[70:, ['男','女']]