2つのデータフレームを1つに結合(行、列の追加)
機械学習などを行うとき、複数のデータを1つにまとめたりしたい時があります。その時に便利なのがPandasのconcatです。
やりたいこと
こんな感じで、2つのデータフレームを1つに結合。

コード紹介
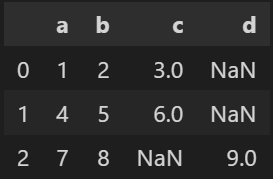
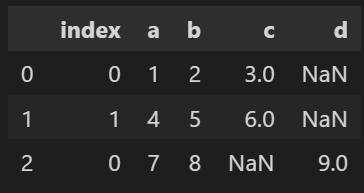
# import import pandas as pd # データセットを作る df1 = pd.DataFrame({'a':[1,4], 'b':[2,5], 'c':[3,6]}) df2 = pd.DataFrame({'a':[7], 'b':[8], 'd':[9]}) # データの結合(行) df3 = pd.concat([df1, df2], axis=0, join='outer') # axis, joinは省略可 # インデックス初期化 df3 = df3.reset_index() # 結合前のindexが不要な場合はdf3.reset_index(drop=True) df3
出力結果
少し解説
concatの引数 join について
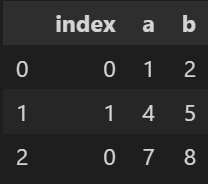
デフォルトはouterですが、innerとすることで内部結合(共通している列だけ残す)になります。
今回の例の場合、'a'と'b'が共通なので、以下のようになります。
python df3 = pd.concat([df1, df2], axis=0, join='inner')
concatの引数 axis について
デフォルト0の場合行に追加していきますが、1にすると列に追加になります。
python df3 = pd.concat([df1, df2], axis=1, join='outer')
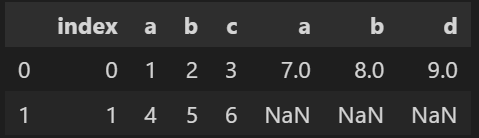
※この場合列aや列bが重複してしまうので、あまり良い例ではありません。
インデクスの初期化(reset_index)について
reset_index()を入れないと、以下のようにインデックスが結合前のdf1, df2のインデックスを引き継ぎ、重複してしまいます。
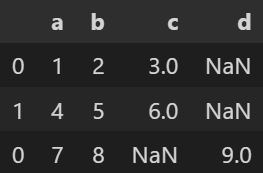
そのため、結合した後は必ずreset_index() を行いましょう。
結合前のインデックスはindexという列名でデータフレームに保管されますが、不要な場合は python reset_index(drop=True)とします。