astypeで数値型を文字列型に変換
前回紹介したstr関数(contains startswith endwith matchなど)は、文字列型にしか使えません。
Pandasでread_excelやread_csvなどをすると自動的に型を割り当ててくれるので、便利ではあるのですが数値型にも上記の関数を使い時もあります。
その方法をお伝えします。
コード紹介
# インポート import pandas as pd # 列の最大表示数を7に設定 pd.set_option('display.max_columns', 7) # 列の最大表示数を5に設定 pd.set_option('display.max_rows', 5) # ファイルの取り込み df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3) print('【すべてのデータを表示】') print(df) df_contain = df[df['男'].astype(str).str.startswith('22')] print('\n\n【男が「22」から始まるものを表示】') print(df_contain)
出力結果
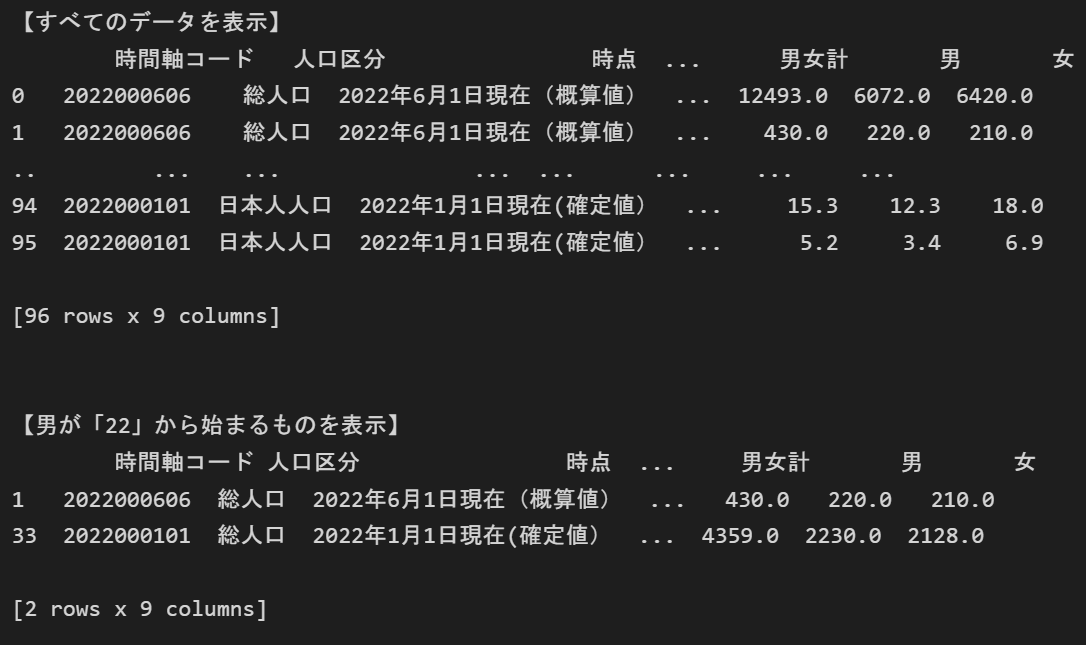
少し解説
df['男'] で列名「男」の中身を取り出します。
そのあとに.astype(str)を入れることで、文字列型に変換します。
よく使うものは以下です。
- str: 文字列
- int: 整数(int32で扱う)
- float: 浮動小数点(float64で扱う)
その後にstr関数を使い、文字列のフィルタをかけています。
(この場合だと22から始まるもの)
ちなみにprintに書いている\nは改行の意味です。
Pandasでフィルタ操作(条件によるデータの絞り込み)
Excelでいうフィルタ機能をPythonで実現していきます。 データ操作は、いつも通りPandasで行います。
コード紹介
# インポート import pandas as pd # 列の最大表示数を7に設定 pd.set_option('display.max_columns', 7) # 列の最大表示数を5に設定 pd.set_option('display.max_rows', 5) # ファイルの取り込み df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3) print('すべてのデータを表示') print(df) df_equal = df[df['人口区分'] == '総人口'] print('人口区分が「総人口」のものを表示') print(df_equal) df_contain = df[df['人口区分'].str.contains('日本')] print('人口区分に「日本」が含まれるものを表示') print(df_contain) df_range = df[(df['男女計'] >= 20) & (df['男女計'] < 40)] print('男女計が20以上40未満のものを表示') print(df_range)
出力結果

少し解説
文字列の条件
str関数の中にいくつか文字の条件を入れることができます。
条件の追加
今回は&をつけてAND条件をコードで紹介しました。
OR条件は|になります。
注意点として、 必ず1つの条件文を()で囲みましょう 。
set_optionでPandasデータの出力結果を省略させない
Pandasはデータ成型に非常に便利ですが、データを表示する時に良きに計らい勝手に省略してくれます。
ざっくり見るのにはよいのですが、やはりExcelのようにデータを全部見たいときありますよね。
困りごと
 このような形で、11列目~20列目、5行目~93行目が省略されてしまいます。
このような形で、11列目~20列目、5行目~93行目が省略されてしまいます。
解決策(コード紹介)
# インポート import pandas as pd # 列の最大表示数を100に設定 pd.set_option('display.max_columns', 100) # 列の最大表示数を100に設定 pd.set_option('display.max_rows', 100) # ファイルの取り込み df = pd.read_excel("sample_data.xlsx") # 結果の表示 df
出力結果
 すべて表示してくれました。
すべて表示してくれました。
少し解説
set_optionを使うとPandasの設定を変えることができます。
python reset_option('all')とすると、設定値をすべてリセットできます。
Pandasを使ってExcelデータを取り込み&データベース化
データ分析をする時にもPythonは便利です。
Excelでできるようにフィルタ、ソートなどの整形、グラフ化だけでなく、機械学習などの応用もできますし、Excelで取り扱えない100万行以上のビッグデータの解析にも活用できます。
使用するデータ
総務省統計局が出している人口推計のデータを使用します。
2022年6月のデータは以下からダウンロードできます。
人口推計 各月1日現在人口 月次 2022年6月 | ファイル | 統計データを探す | 政府統計の総合窓口
ソースコード紹介
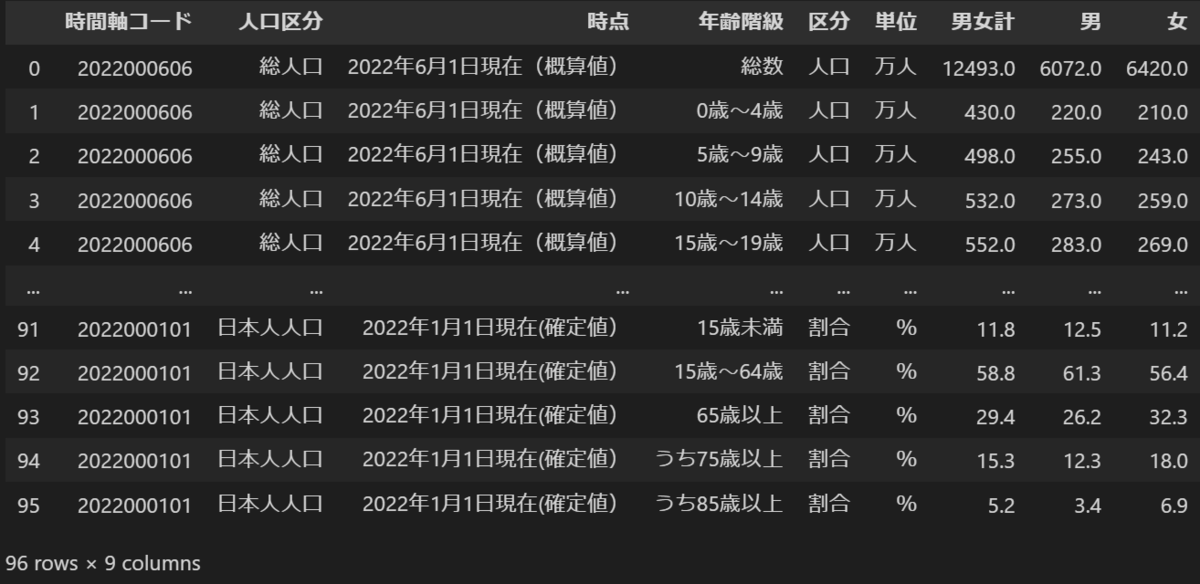
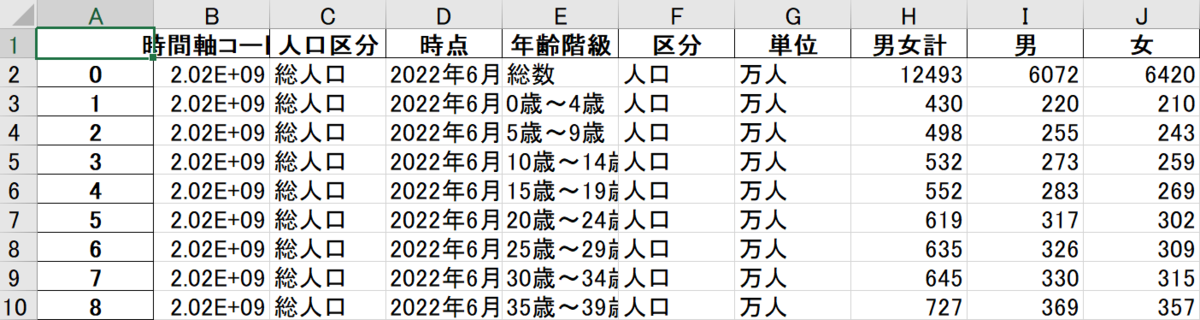
# パッケージのインストール(初回のみ) !pip install pandas # データの取り込み、整形などができるパッケージ !pip install openpyxl # Excelの取り込みに必要 # インポート import pandas as pd # ファイルの取り込み # skiprows: 初めの行を指定された数だけ取り除く # skipfooter: 最後の行を指定された数だけ取り除く # header: 列名とする行番号。デフォルトが0なので省略可。列名がない場合はNoneにする # usecols: 取り込む列A列からH列とI列を取り込む。デフォルトでは自動ですべての列を取得するため、こちらも省略可。 df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3, header=0, sheet_name="05k2-3", usecols="A:H,I") # ファイルの書き出し df.to_excel('result.xlsx') # 結果の表示 df
結果
コンソール
result.xlsx
少し解説
read_excel()
この人口推計のデータ、少しクセがあります。
はじめ3行に表の説明が書かれています。

最後の3行も注意書きがあります。

こういったデータは分析するときに邪魔になります。
read_excel関数の引数をうまく使えば、たった1行で取り込む際にこういった余計なデータを削除して分析用のデータに整形することができます。
それぞれの引数はコードのコメントアウトに書いていますので、そちらを参照ください。
read_csv()
read_excelの代わりにread_csvを使うと、CSVデータの取り込みも可能です。
ただ、python usecols="A:H,I"のようにアルファベットの列番号を使うことができないため、python usecols=[0,1,2,3,4]のように数字の列番号を使用します。(範囲指定ができないのが少しネック)
色調で簡易的な物体検出
今日は色調を見て赤色のものを検出するプログラムを紹介します。 色で検知するにはHSVを利用します。こちらもまた後程紹介します。
コード紹介
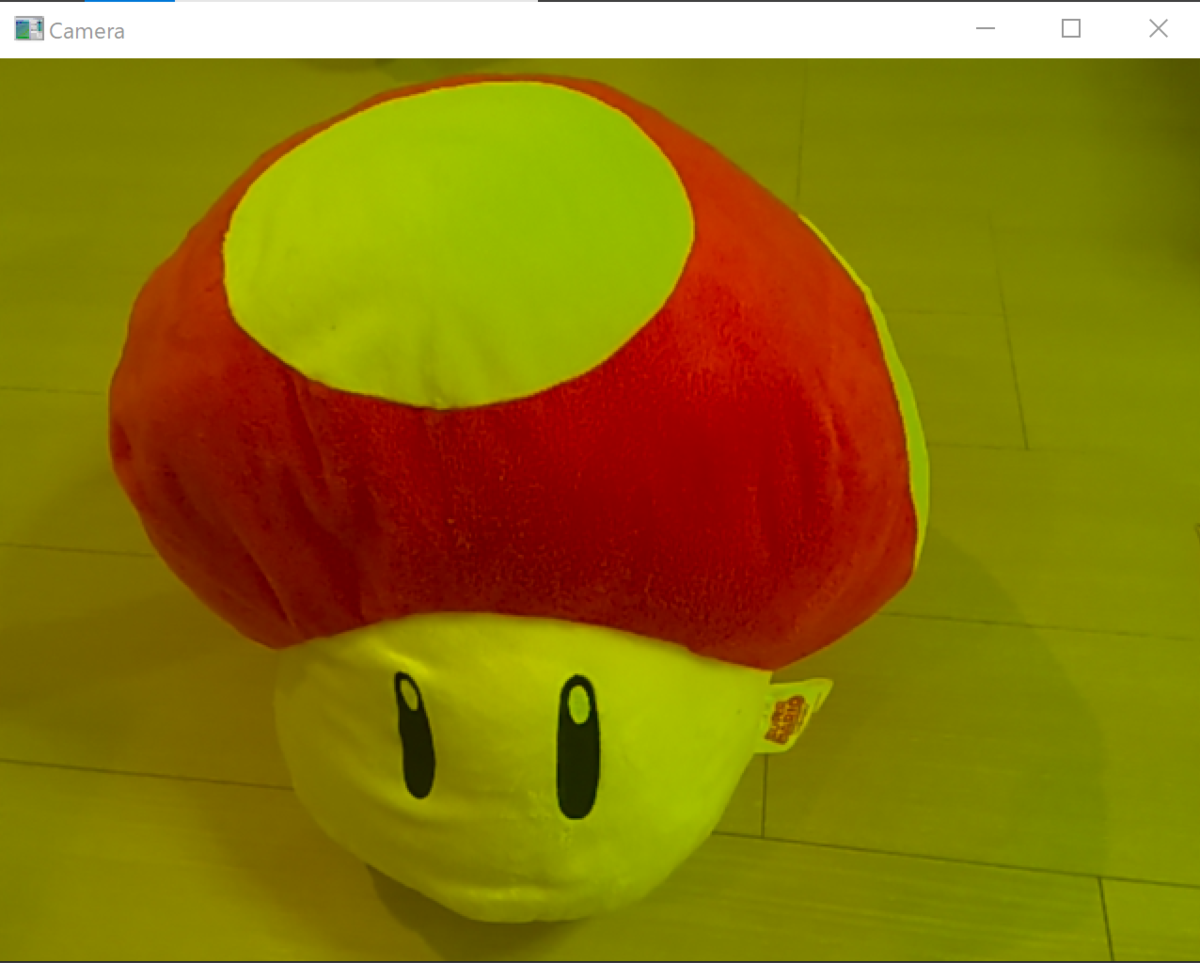
# import import cv2 # 検知する範囲の指定 target_x1, target_x2, target_y1, target_y2 = 300, 350, 200, 250 # Webカメラから入力を開始 cap = cv2.VideoCapture(0) while True: # カメラの画像を読み込む _, frame = cap.read() # 判定個所のトリミング frame_judge = frame[target_y1:target_y2, target_x1:target_x2] # HSV変換 hsv = cv2.cvtColor(frame_judge, cv2.COLOR_BGR2HSV) # HSVそれぞれを一次元配列に格納 h, s, v = hsv[:, :, 0].flatten(), hsv[:, :, 1].flatten(), hsv[:, :, 2].flatten() # HSVそれぞれの平均 h_mean, s_mean, v_mean = h.mean(), s.mean(), v.mean() # 検知範囲を矩形で表示 cv2.rectangle(frame, (target_x1, target_y1), (target_x2, target_y2), (255, 255, 255), thickness=2) # print(h_mean, s_mean, v_mean) if( ( 0 <= h_mean < 30 or 150 <= h_mean < 180 ) and s_mean >= 100 ): # 文字の出力 cv2.putText(frame, text='Red!', org=(50, 50), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1.0, color=(0, 0, 255), thickness=2) # ウィンドウに画像を出力 cv2.imshow('Camera', frame) # ESCかEnterキーが押されたらループを抜ける k = cv2.waitKey(500) & 0xFF # 500msec毎 if k == 27 or k == 13: break cap.release() # カメラを開放 cv2.destroyAllWindows() # ウィンドウを破棄
出力結果

 枠内に赤色が入った時に「Red!」と表示されるようになりました。
枠内に赤色が入った時に「Red!」と表示されるようになりました。
少し解説
HSVについて
色の表現を以下3つの観点で行う方法です。
H: 色相
S: 彩度
V: 明度
Wikipediaの画像にあるように、Sの値が小さいと黒っぽいもしくは白っぽい色になるため、Sは100以上にします。
Hの値は以下の表を参考にしてください。
| 色 | Hの値 |
|---|---|
| 赤 | 0~30, 150~179 |
| 緑 | 30~90 |
| 青 | 90~150 |
関数
flatten() 多次元配列を一次元配列に変換
python hsv[:, :, 1]は[[1,1,...,1][1,1,...,1]]のように多次元になっています。python hsv[:, :, 1].flatten()とすることで、[1,1,...,1]というように一次元の配列にすることができます。
mean() 平均値の計算
上記一次元配列にしたもの(h)に対して、python h.mean()とすることで配列内の平均値を求めることができます。
つまり、検知範囲の中のH(色相)の平均を出していることになります。
cv2.rectangle 画像に四角形を表示
python cv2.rectangle(frame, (target_x1, target_y1), (target_x2, target_y2), (255, 255, 255), thickness=2) で、四角形を表示しています。
第一引数:画像
第二引数:左上の座標
第三引数:右下の座標
第四引数:線の色
第五引数:線の太さ
となります。
cv2.putText 画像にテキストを表示
python cv2.putText(frame, text='Red!', org=(50, 50), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1.0, color=(0, 0, 255), thickness=2)でテキストを表示します。
第一引数:画像
第二引数:表示するテキスト
第三引数:左上の座標
第四引数:フォント種類
第五引数:フォントサイズ
第六引数:テキストの色
第七引数:テキストの太さ
です。
OpenCVで動画を扱う
OpenCVは動画の扱いも比較的楽に行えます。
少しずつ動画処理の記事も増やしていこうと思います。
コード紹介
# import import cv2 import time # 動画データを取り込む # 0以上の数字:Webカメラを入力とする(どの数字かはPC環境による) # './sample.mp4'など動画ファイルを指定:動画ファイルを入力とする cap = cv2.VideoCapture(0) # たまにエラーになるため、表示前に3秒待つ time.sleep(3) while True: # カメラの画像を読み込む _, frame = cap.read() # 青色要素を0にする # frame[:,:,0] = 0 # ウィンドウに画像を出力 cv2.imshow('Camera', frame) # ESCかEnterキーが押されたらループを抜ける k = cv2.waitKey(100) & 0xFF # 100msec確認 if k == 27 or k == 13: break cap.release() # カメラを開放 cv2.destroyAllWindows() # ウィンドウを破棄
出力結果

少し解説
cap = cv2.VideoCapture(0)で動画を取得する準備をします。 中の0は、PCによって変わります。 (私のSurfaceは0がアウトカメラ、1がインカメです。USBでWebカメラを接続すると、おそらく2で取得できると思います)
while True:は無限ループの意味です。
_, frame = cap.read()で動画から画像ファイルとしてキャプチャし、frameに格納します。 1つ目は読み込めたかどうか、True,Falseで返すものですが、今回は使わないので「_」としています。
cv2.waitKey(100) & 0xFFは100msec(0.1秒)キーボードの入力を待つ、ということで、何も入力しなければ次に行く、つまりループに戻ってまた動画をキャプチャして・・・、という繰り返しです。
少し改造
解説で説明したように、結局は動画も1枚1枚の画像にしています。
そのため、今までの画像処理がそのまま使えます。
例えばpython frame[:, :, 0] = 0を追加してみましょう。(コード紹介のコメントアウトを外します。
すると青の要素がなくなった画像が、動画として流れます。
画像の配列をいじって色調を変える
OpenCVのcv2.imreadで画像を取り込むと、画像1ピクセルごとの色情報が配列で読み取られます。
今回はそれを活用して、色調を変えてみます。
画像の配列について
まずOpenCVで読み取った画像をそのまま出力してみます。
# インポート import cv2 # 画像ファイルの読み込み img = cv2.imread("Lenna.jpg") # 表示 img
すると以下のように3次元の配列で表示されます。

少しわかりずらいので、縦2ピクセル、横3ピクセルの画像で説明すると、こんな配列になります。
[
[
[青, 緑, 赤], [青, 緑, 赤], [青, 緑, 赤]
],
[
[青, 緑, 赤], [青, 緑, 赤], [青, 緑, 赤]
]
]
今までも何度か出てきていますが、OpenCVはBGRの順番です。間違えやすいので注意。
赤要素をなくす(0にする)
コード紹介
# インポート import cv2 import matplotlib.pyplot as plt # 画像ファイルの読み込み img = cv2.imread("Lenna.jpg") # サイズを取得 height,width,color = img.shape # 赤要素を0にする img[:, :, 2] = 0 # 配列を表示 print(img) # 画像を出力 plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
出力結果

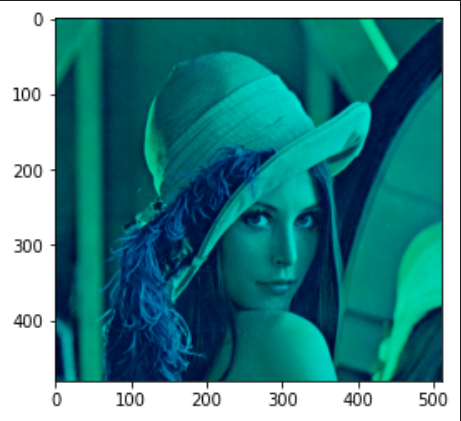
少し解説
img[:, :, 2] = 0で、3次元目の要素2をすべて0にするということになります。 0→青、1→緑、2→赤なので、赤要素を0にするということですね。 1次元目と2次元目の「 : 」は、すべて、という意味になります。
応用
縦0~100ピクセルだけ変える
img[0:100, :, 2] = 0
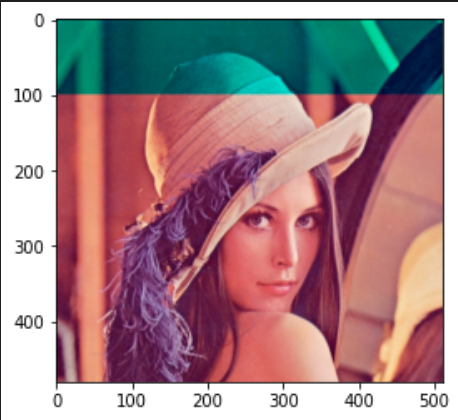
縦0~100ピクセル、横100~300ピクセルだけ変える
img[0:100, 100:300, 2] = 0
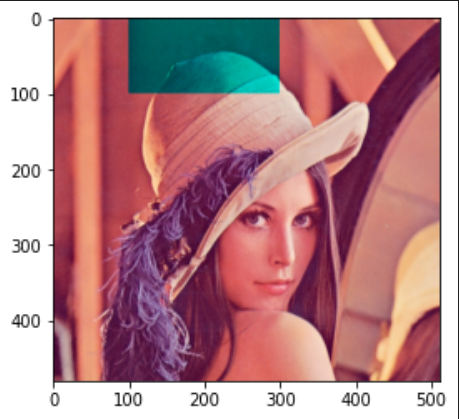
青(0)と赤(2)両方0にする(つまり緑要素だけを取り出す)
img[0:100, 100:300, (0, 2)] = 0
