Pandasを使ってExcelデータを取り込み&データベース化
データ分析をする時にもPythonは便利です。
Excelでできるようにフィルタ、ソートなどの整形、グラフ化だけでなく、機械学習などの応用もできますし、Excelで取り扱えない100万行以上のビッグデータの解析にも活用できます。
使用するデータ
総務省統計局が出している人口推計のデータを使用します。
2022年6月のデータは以下からダウンロードできます。
人口推計 各月1日現在人口 月次 2022年6月 | ファイル | 統計データを探す | 政府統計の総合窓口
ソースコード紹介
# パッケージのインストール(初回のみ) !pip install pandas # データの取り込み、整形などができるパッケージ !pip install openpyxl # Excelの取り込みに必要 # インポート import pandas as pd # ファイルの取り込み # skiprows: 初めの行を指定された数だけ取り除く # skipfooter: 最後の行を指定された数だけ取り除く # header: 列名とする行番号。デフォルトが0なので省略可。列名がない場合はNoneにする # usecols: 取り込む列A列からH列とI列を取り込む。デフォルトでは自動ですべての列を取得するため、こちらも省略可。 df = pd.read_excel("05k2-3.xlsx", skiprows=3, skipfooter=3, header=0, sheet_name="05k2-3", usecols="A:H,I") # ファイルの書き出し df.to_excel('result.xlsx') # 結果の表示 df
結果
コンソール
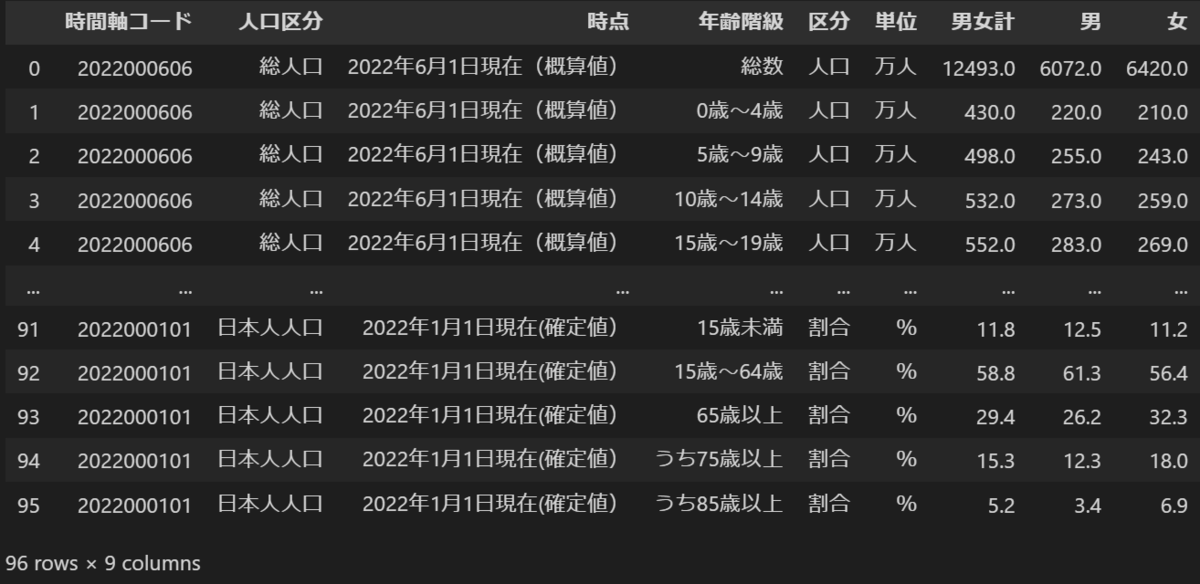
result.xlsx
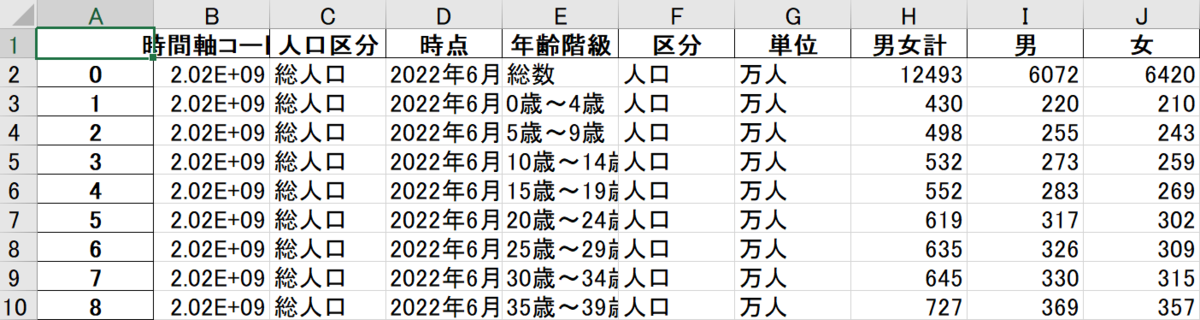
少し解説
read_excel()
この人口推計のデータ、少しクセがあります。
はじめ3行に表の説明が書かれています。

最後の3行も注意書きがあります。

こういったデータは分析するときに邪魔になります。
read_excel関数の引数をうまく使えば、たった1行で取り込む際にこういった余計なデータを削除して分析用のデータに整形することができます。
それぞれの引数はコードのコメントアウトに書いていますので、そちらを参照ください。
read_csv()
read_excelの代わりにread_csvを使うと、CSVデータの取り込みも可能です。
ただ、python usecols="A:H,I"のようにアルファベットの列番号を使うことができないため、python usecols=[0,1,2,3,4]のように数字の列番号を使用します。(範囲指定ができないのが少しネック)